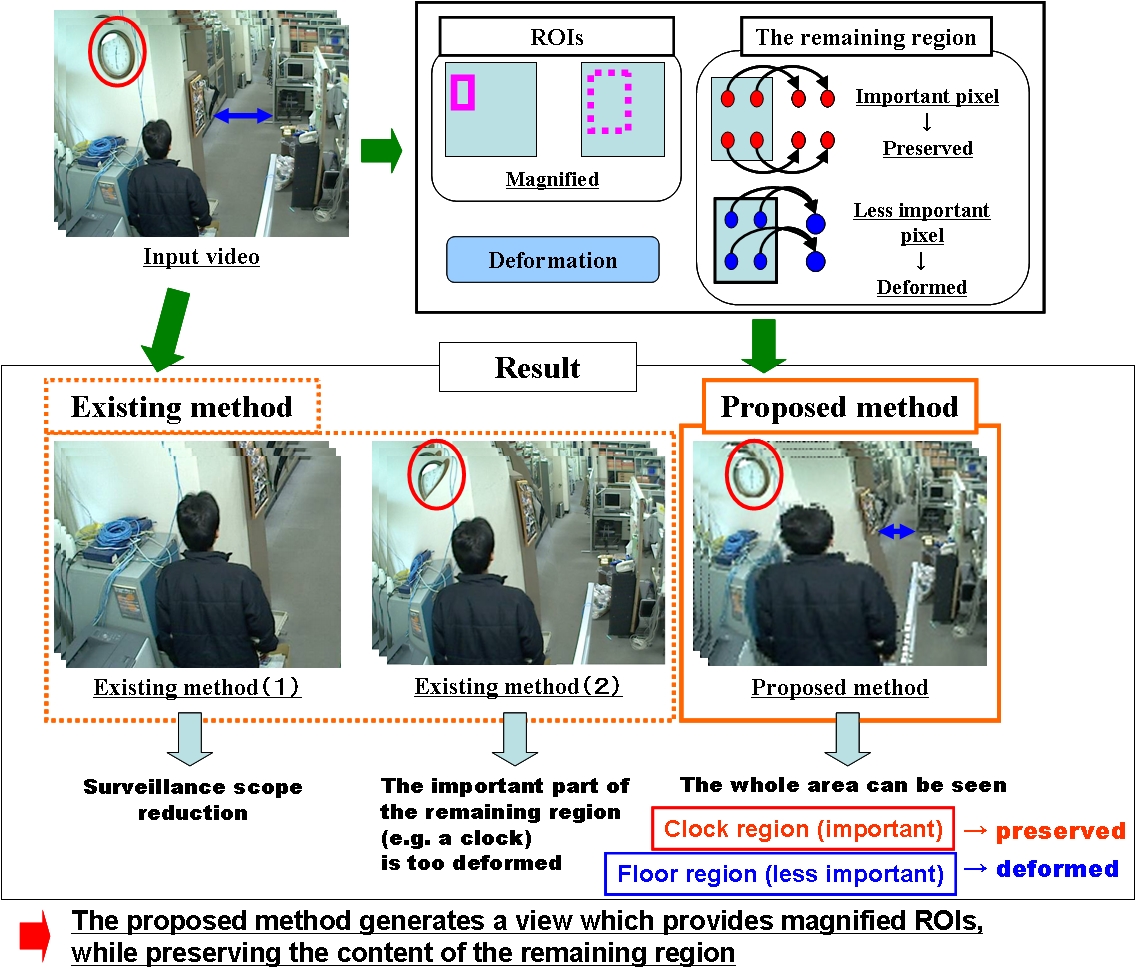
"Content preserving" zoom-in view generation
Video surveillance has been widely used in many places today. In surveillance videos, moving objects or persons should generally be paid attention by viewers, and these regions can be defined as the regions of interest (ROIs). We are interested in generating a zoom-in view which provides magnified ROIs to help viewers observe these regions more easily.
In this research, we propose a technique for generating a "content-preserving" zoom-in view which automatically provides magnified ROIs and at the same time preserves the content of the remaining region based on its importance score.
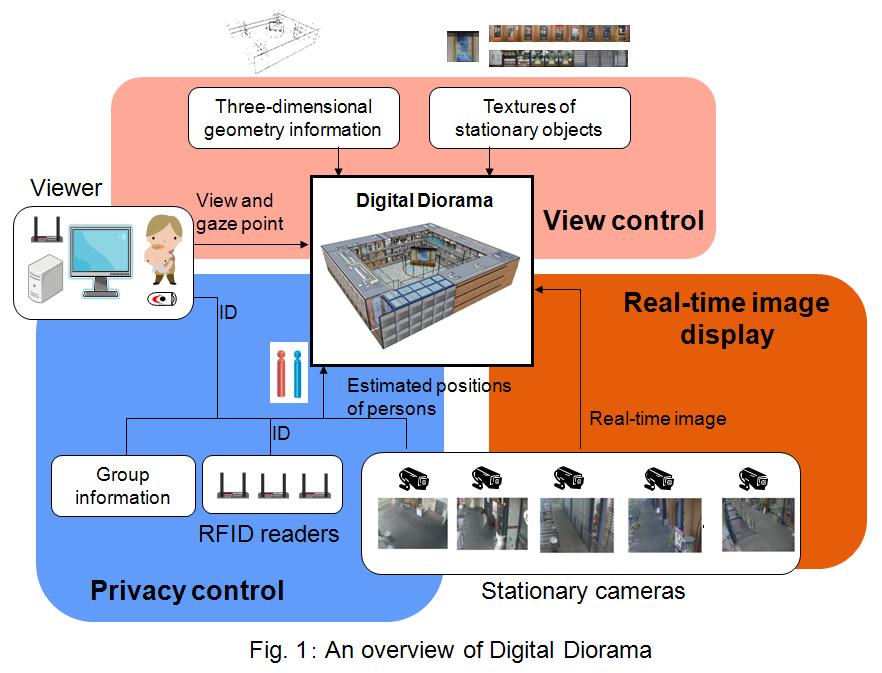
Three-dimensional visualization of public spaces by integrating information from sensors (Digital Diorama)
In recent years, many sensors such as stationary cameras, RFID readers, and GPS receivers are installed around the world. In this research, we propose three-dimensional view "Digital Diorama," where viewers can see at a glance how people are moving around the monitored space without violating their privacy. In Digital Diorama, real-time information obtained from stationary cameras and RFID readers installed in public spaces is presented according to three-dimensional geometry information with the following features: (1) view control, (2) real-time images display, and (3) privacy control.

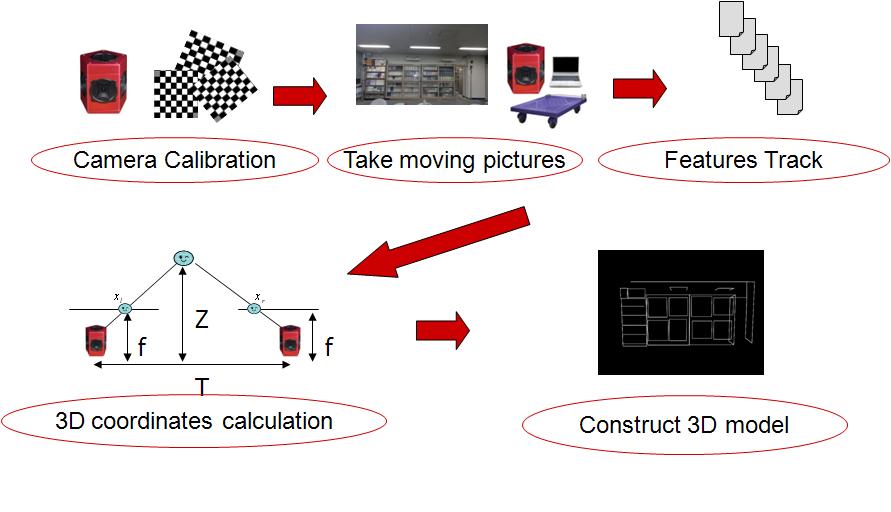
Construction of three-dimensional models of environments
In recent years, 3D models of high visual quality are strongly required in the areas of augmented reality and mixed reality. In order to construct a 3D model of high visual quality, a lot of efforts have been paid for measuring exact locations and sizes of the objects in environments. For reducing such efforts, a method called "Structure from Motion (SfM)" has been proposed, which construct a 3D model by integrating multi-view images obtained by a moving camera.
SfM is a general method, which can be applied to arbitrary shaped objects. However, the method requires large computational load. We focus on environments in which each surface of objects can be approximated by a rectangular, and consider a method for 3D modeling with less computational load.
 A target environment.
|
A result.
|
Back