Multimedia synchronization for video content generation
Overview
Video contents are generally created by mixing multiple media streams such as video clips, music clips, and transition effects.
In this research, we propose a support system for creating video contents of good expressive quality based on the audio-visual co-occurrence relations and the temporal patterns learned from professionally created example video contents.
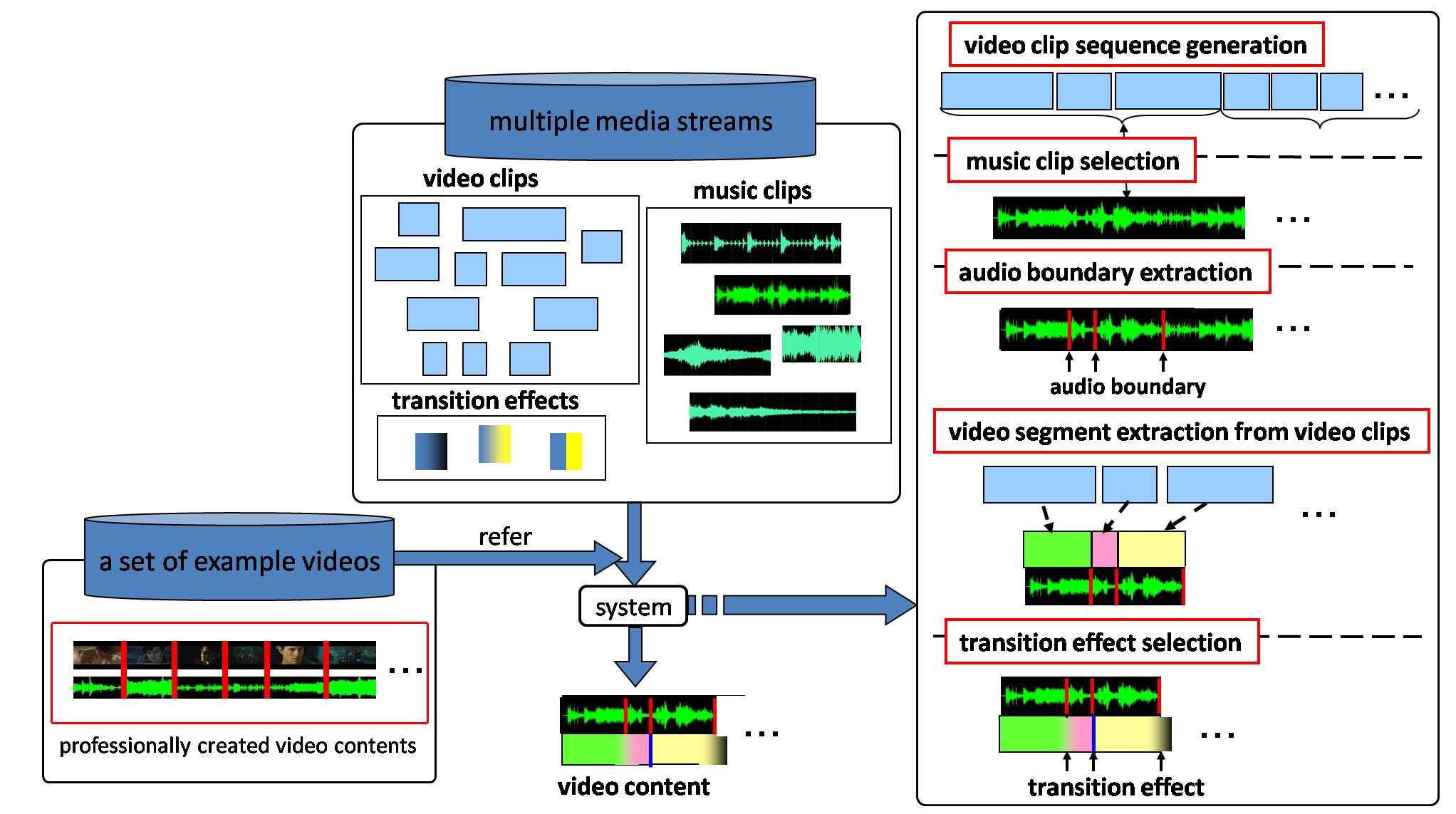
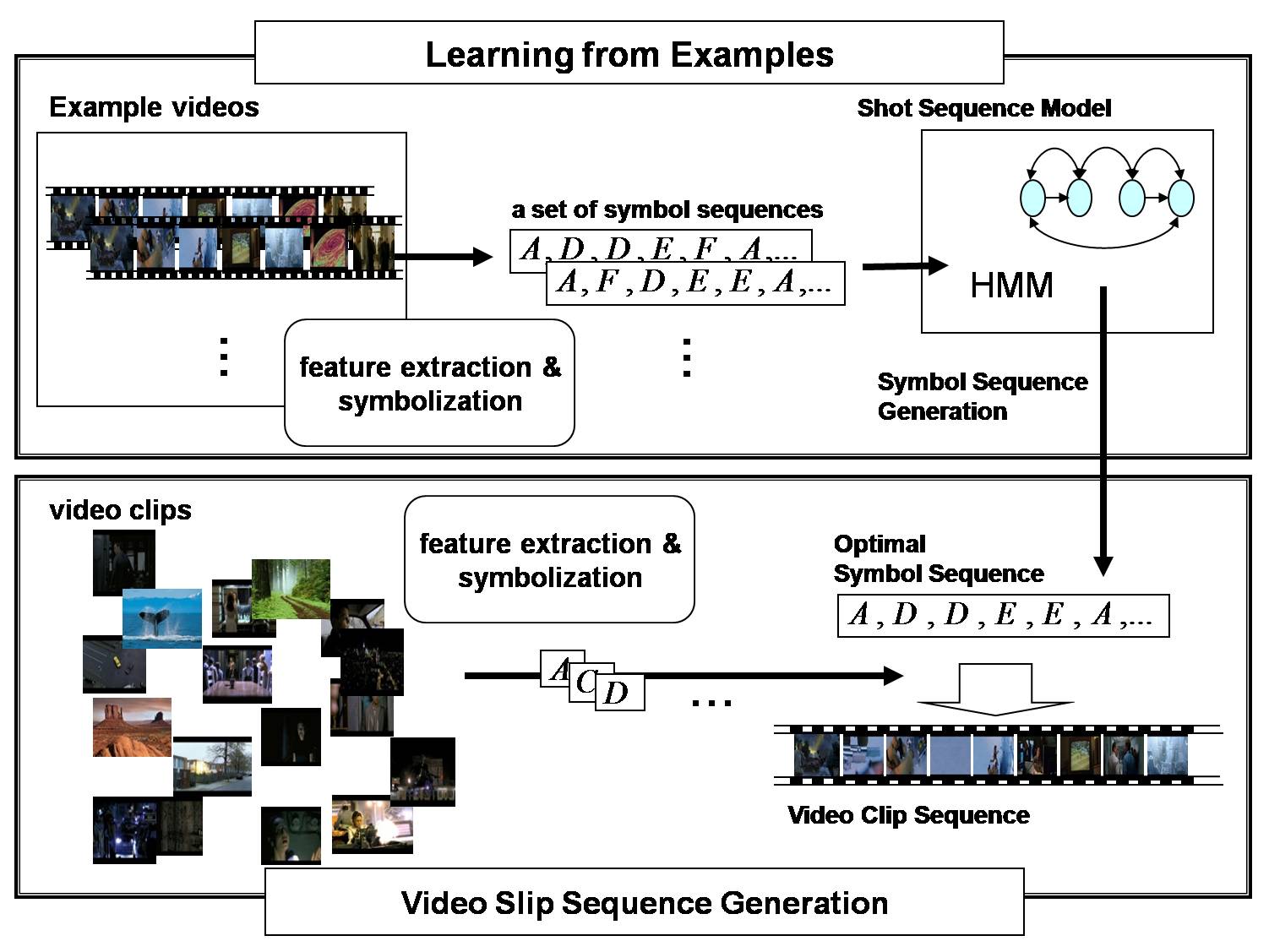
Video clip sequence generation
Video clips are usually sequentially arranged according to certain rules such as film grammar. In order to imitate such techniques in creating a video clip sequence, we firstly transform shot sequences of example videos into symbol sequences and learn their temporal patterns by Hidden Markov Model (HMM). Then, an optimal symbol sequence is generated by the learned HMM and an appropriate video clip is selected for each symbol from a set of video clips.
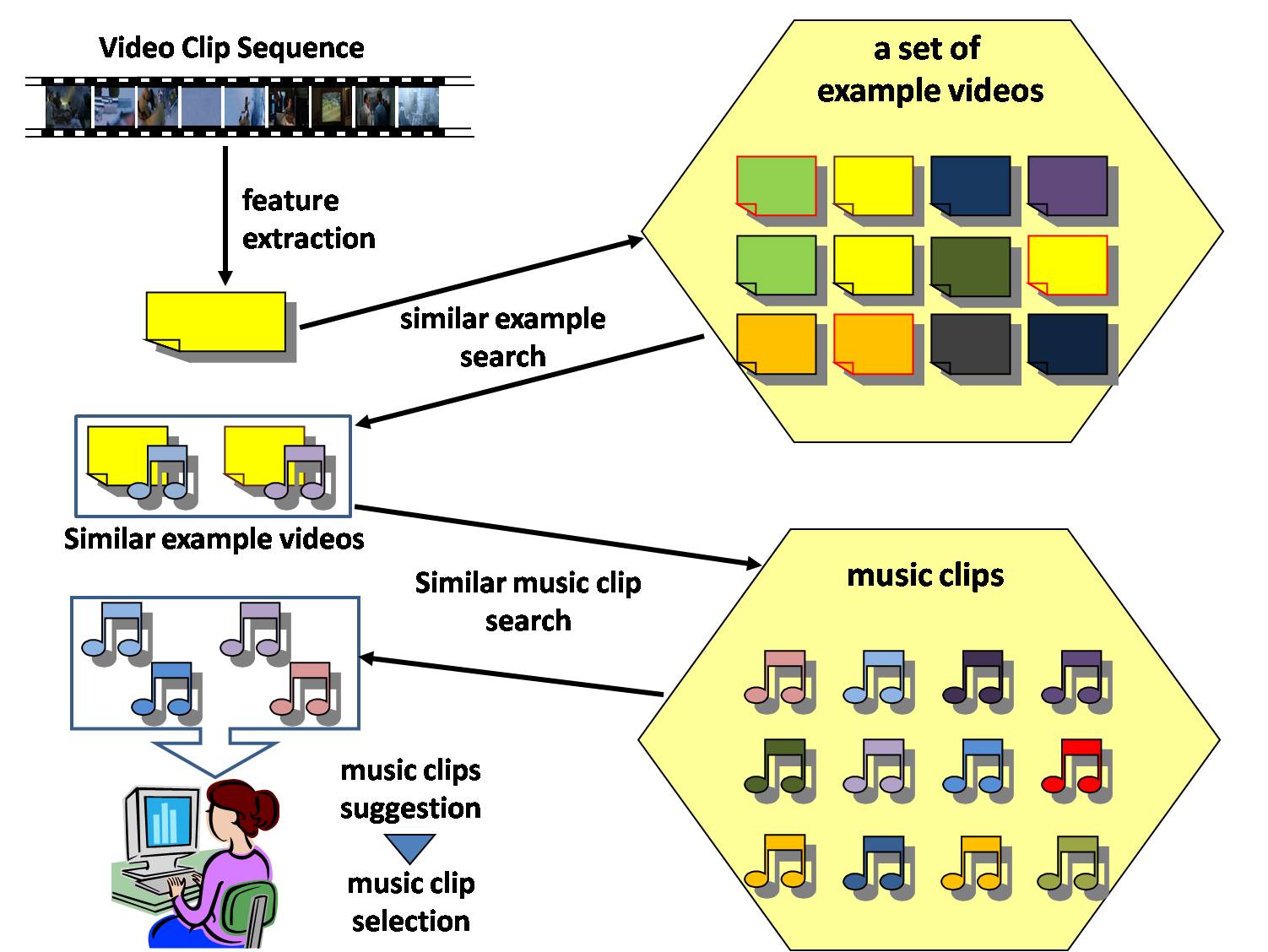
Music clip selection
Mixing video clips with appropriate music often enhances the expressive quality of the video content. We firstly search example videos similar to the generated video clip sequence, and then search music clips similar to the music mixed with the example videos as the candidate music clips. Finally, the user selects a music clip from the candidate music clips.
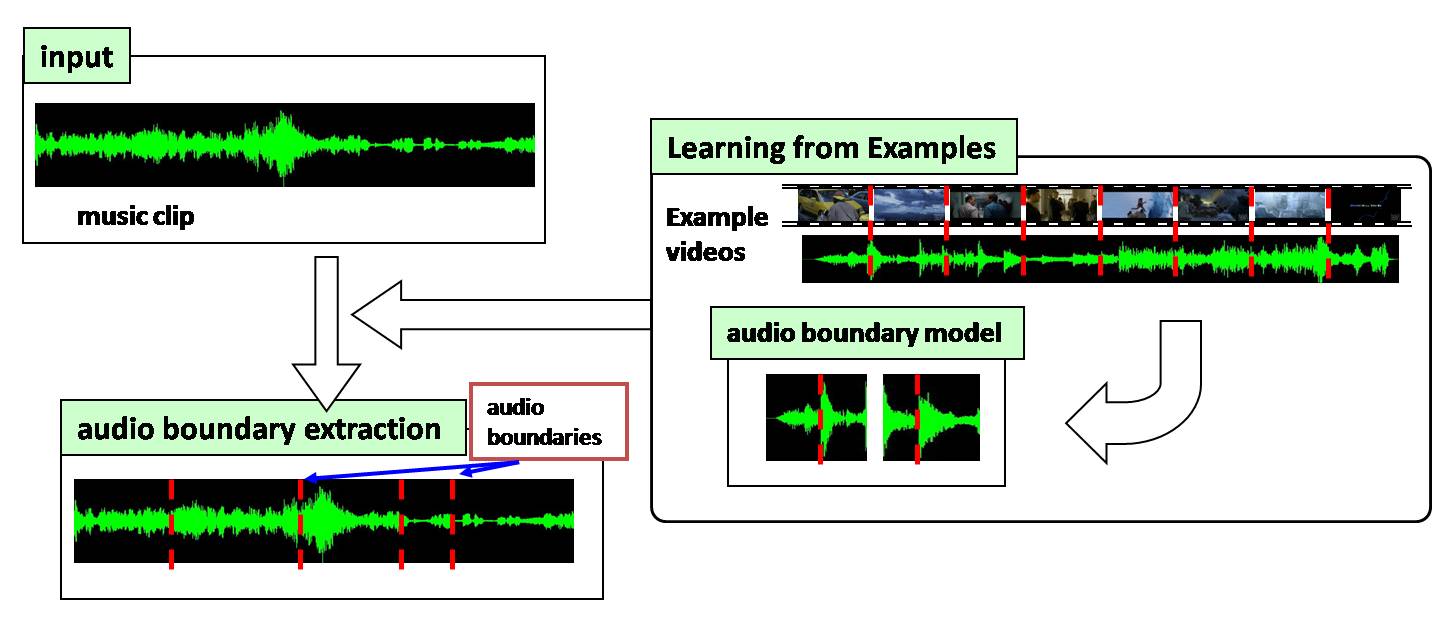
Audio boundary extraction
Next, we synchronize video clip boundaries and audio boundaries in the selected music clip.
To synchronize boundaries, we firstly learn audio change patterns around shot boundaries in example videos by Markov Chain Model (MCM) . Then, audio frames with similar change patterns are extracted from the music clip as the audio boundaries.
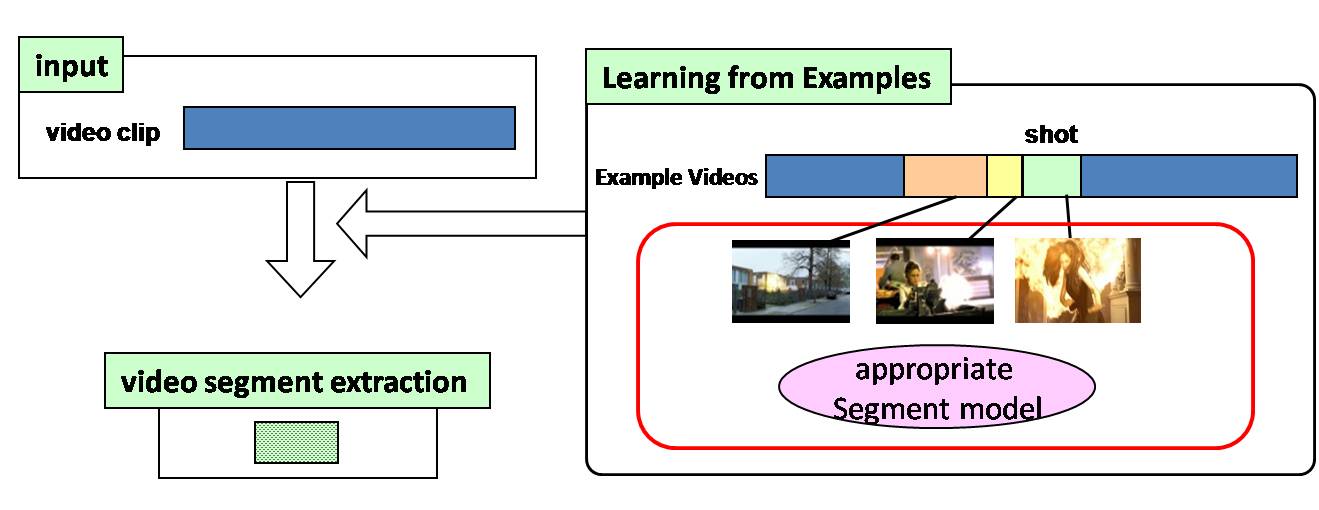
Video segment extraction from video clips
To synchronize video clip boundaries to the audio boundaries extracted from the music clip, we shorten each video clip by extracting an appropriate video segment based on HMM representing the temporal patterns of frame-based features in shots in example videos.
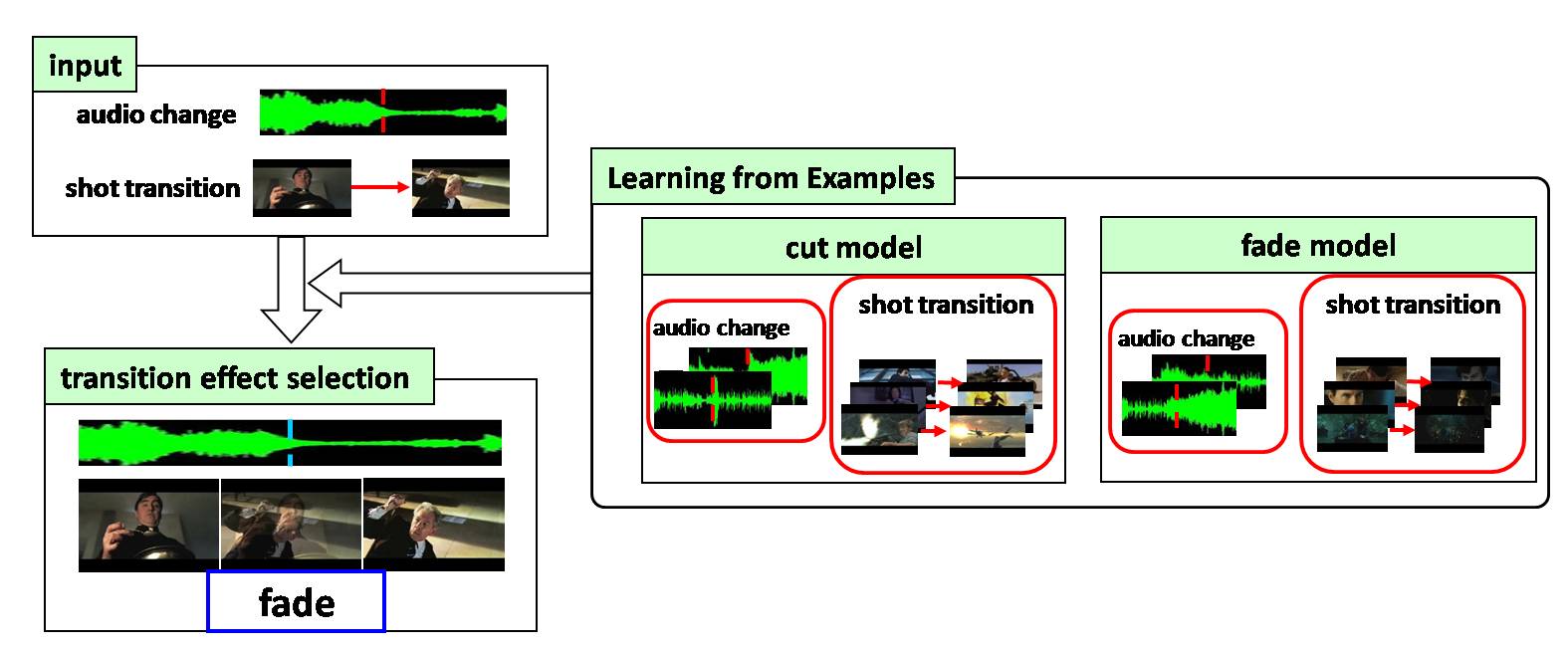
Transition effect selection
Finally, we generate transition effect models using MCMs, which learn the audio change patterns and the transition of shot categories around the shot boundaries in example videos. Then, by using the generated transition effect models, a transition effect is determined based on the audio change and transition of shot categories around each video clip boundary.
Back